Streaming Analytics
with Scala and Spark Structured Streaming

Bas Geerdink | December 13, 2019 | Functional Scala
Who am I?
{
"name": "Bas Geerdink",
"role": "Technology Lead",
"background": ["Artificial Intelligence",
"Informatics"],
"mixins": ["Software engineering",
"Architecture",
"Management",
"Innovation"],
"twitter": "@bgeerdink",
"linked_in": "bgeerdink"
}
Fast Data Use Cases
| Sector | Data source | Pattern | Notification |
|---|---|---|---|
| Finance | Payment data | Fraud detection | Block money transfer |
| Finance | Clicks and page visits | Trend analysis | Actionable insights |
| Insurance | Page visits | Customer is stuck in a web form | Chat window |
| Healthcare | Patient data | Heart failure | Alert doctor |
| Traffic | Cars passing | Traffic jam | Update route info |
| Internet of Things | Machine logs | System failure | Alert to sys admin |
Apache Spark libraries
Spark Structured Streaming utilizes Spark SQL Datasets and DataFrames, which no longer inherit from the 'batch-driven' RDD

Parallelism
- To get high throughput, we have to process the events in parallel
- Parallelism can be configured on cluster level (YARN) and on job level (number of worker threads)
val conf = new SparkConf()
.setMaster("local[8]")
.setAppName("FraudNumberOfTransactions")
./bin/spark-submit --name "LowMoneyAlert" --master local[4]
--conf "spark.dynamicAllocation.enabled=true"
--conf "spark.dynamicAllocation.maxExecutors=2" styx.jar
Spark-Kafka integration
- A Fast Data application is a running job that processes events in a data store (Kafka)
- Jobs can be deployed as ever-running pieces of software in a big data cluster (Spark)
- The basic pattern of a job is:
- Connect to the stream and consume events
- Group and gather events (windowing)
- Perform analysis (aggregation) on each window
- Write the result to another stream (sink)
Connect to Spark and Kafka
// connect to Spark
val spark = SparkSession
.builder
.config(conf)
.getOrCreate()
// for using DataFrames
import spark.sqlContext.implicits._
// get the data from Kafka: subscribe to topic
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "transactions")
.option("startingOffsets", "latest")
.load()
Data Preparation
// split up a tweet in separate words
val tweetStream = df
.map(_.getString(1)) // get value
.map(Tweet.fromString)
.filter(_.isDefined).map(_.get)
// create multiple TweetWord objects from 1 tweet
.flatMap(tweet => {
val words = tweet.text
.toLowerCase()
.split("[ \\t]+") // get words from tweet
words.map(word => TweetWord(tweet.created_at, word))
})
.filter(tw => !wordsToIgnore.contains(tw.word)
&& tw.word.length >= minimumWordLength)
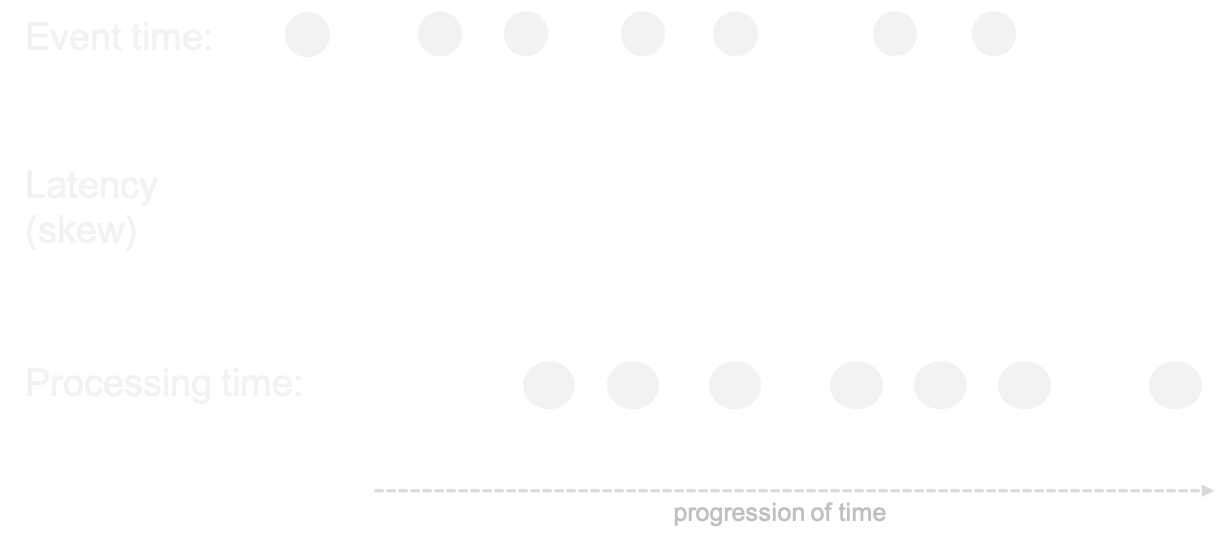
Event time
- Events occur at certain time ⇛ event time
- ... and are processed later ⇛ processing time
Windows
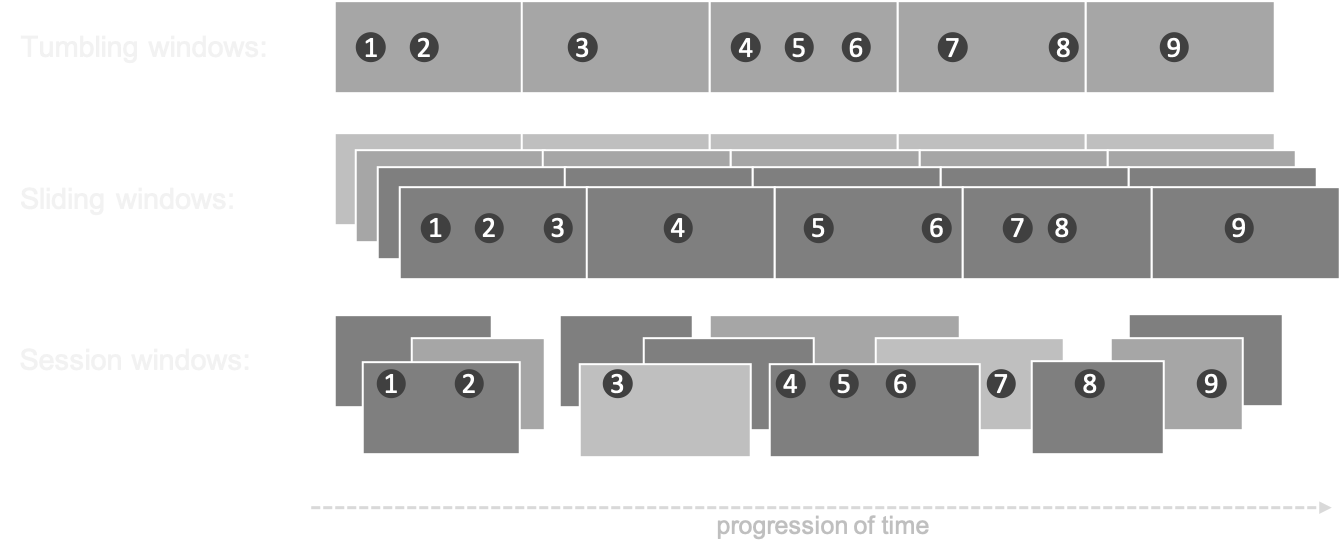
- In processing infinite streams, we usually look at a time window
- A windows can be considered as a bucket of time
- There are different types of windows:
- Sliding window
- Tumbling window
- Session window
Windows
Windows
Example: sliding window of 1 hour, evaluated every 15 minutes. The event time is stored in the field 'created_at'. Aggregation is done by counting the words per group, per window.
// aggregate, produces a sql.DataFrame
val windowedTransactions = tweetStream
.groupBy(
window($"created_at", "1 hour", "15 minutes"),
$"word")
.agg(count("word") as "count", $"word", $"window.end")
Watermarks
- Watermarks are timestamps that trigger the computation of the window
- They are generated at a time that allows a bit of slack for late events
- Any event that reaches the processor later than the watermark, but with an event time that should belong to the former window, is ignored
Event Time and Watermarks
Example: sliding window of 60 seconds, evaluated every 30 seconds. The watermark is set at 1 second, giving all events some time to arrive.
// aggregate, produces a sql.DataFrame
val windowedTransactions = tweetStream
.withWatermark("created_at", "1 minute") // <--- watermark
.groupBy(
window($"created_at", "1 hour", "15 minutes"),
$"word")
.agg(count("word") as "count", $"word", $"window.end")
Model scoring
- To determine the follow-up action of a aggregated business event (e.g. pattern), we have to enrich the event with customer data
- The resulting data object contains the characteristics (features) as input for a model
- To get the features and score the model, efficiency plays a role again:
- Direct database call > API call
- In-memory model cache > model on disk
PMML
- PMML is the glue between data science and data engineering
- Data scientists can export their machine learning models to PMML (or PFA) format
from sklearn.linear_model import LogisticRegression
from sklearn2pmml import sklearn2pmml
events_df = pandas.read_csv("events.csv")
pipeline = PMMLPipeline(...)
pipeline.fit(events_df, events_df["notifications"])
sklearn2pmml(pipeline, "LogisticRegression.pmml", with_repr = True)
PMML
Openscoring.io
def score(event: RichBusinessEvent, pmmlModel: PmmlModel): Double = {
val arguments = new util.LinkedHashMap[FieldName, FieldValue]
for (inputField: InputField <- pmmlModel.getInputFields.asScala) {
arguments.put(inputField.getField.getName,
inputField.prepare(customer.all(fieldName.getValue)))
}
// return the notification with a relevancy score
val results = pmmlModel.evaluate(arguments)
pmmlModel.getTargetFields.asScala.headOption match {
case Some(targetField) =>
val targetFieldValue = results.get(targetField.getName)
case _ => throw new Exception("No valid target")
}
}
}
Thanks!
Read more about streaming analytics at:
Source code and presentation are available at: